Fast.ai:从零开始学深度学习 | 资源帖(新手怎么开始学编程)从零开始学习ps,
导读:近日,Fast.ai 发布一门新课程——从零开始学深度学习(Deep Learning from the Foundations),该课程由 Jeremy Howard 教授,展示了如何从头开始构建最先进的深度学习模型。
课程简介介绍道,本课程将从实现矩阵乘法和反向传播基础开始,到高性能混合精度训练,最新的神经网络架构和学习技术,以及介于两者之间的所有内容。它涵盖了许多构成现代深度学习基础的最重要的学术论文,使用“代码优先”教学方法,每个方法都从头开始在 Python 中实现并进行详解(还将讨论许多重要的软件工程技术)。整个课程包括大约 15 个课时和数十个交互式 notebooks,且完全免费、无广告,作为社区服务供使用。前五课时使用 Python、PyTorch 和 fastai 库;最后两节课使用 Swift for TensorFlow,并由 Jeremy Howard 和与Swift、clang 和 LLVM 的创建者 Chris Lattner 共同教授。
 打开凤凰新闻,查看更多高清图片
打开凤凰新闻,查看更多高清图片
本课程是 fast.ai 2019 年深度学习系列的第二部分,第 1 部分“编码实用深度学习”(https://course.fast.ai/)于 1 月发布,是必学先修课。

从某些方面来说,基础深度学习的目的与第 1 部分相反。这一次,我们不会学习可以马上使用的实践,而是打下学习的基础。这一点现在特别重要,因为这个领域正在快速发展。在这个新课程中,我们将学习如何实现 fastai 和 PyTorch 库中的许多内容。事实上,我们将重新实现 fastai 库的重要子集!在此过程中,我们将练习实复现论文,这是掌握最先进模型时需要掌握的重要技能。
在最后两节课不仅涵盖 TensorFlow 和 Swift 的新教材,还要从头开始创建一个新的 fastai Swift库,并在 Swift for TensorFlow 中添加许多新功能,由 Google Brain 的 Swift for TensorFlow小组与 fast.ai 合作完成。今天,谷歌发布了一个新版本的 Swift for TensorFlow(0.4)以配合新课程。有关 Swift for TensorFlow版本和课程的更多信息,请查看 TensorFlow 博客文章(https://medium.com/tensorflow/fast-ais-deep-learning-from-the-foundations-with-swift-for-tensorflow-3ee7dfb68387)。
本文的其余部分,我将简要介绍本课程中可能涉及的一些主题。有任何疑问,可在论坛讨论(https://forums.fast.ai/c/part2-v3)。
第8课:矩阵乘法;正推法和逆推法
我们的主要目标是建立一个完整的系统,让 Imagenet 准确性和速度达到世界一流。所以我们需要覆盖很多领域。
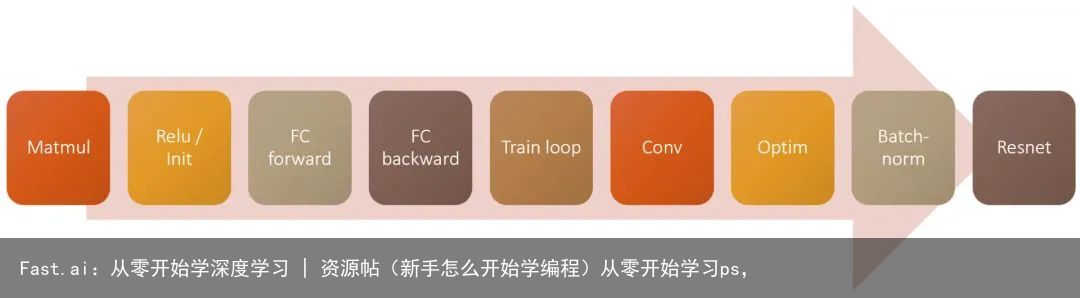
训练 CNN 的路线图
第一步是矩阵乘法!我们将逐步重构并加速第一个 Python 和矩阵乘法,学习broadcasting 和爱因斯坦求和,并用它来创建一个基本的神经网络前向传递,包括初步了解神经网络是如何初始化的(我们将在未来的课程中深入探讨这个主题)。

Broadcasting 和 einsum 加速矩阵相乘
然后,我们将实现向后传递,包括对链规则的简要回顾(实际上所有向后传递都是)。之后,我们将重构向后的路径,使其更加灵活和简洁,最后我们将看到这些如何转换为 PyTorch 实际工作的方式。
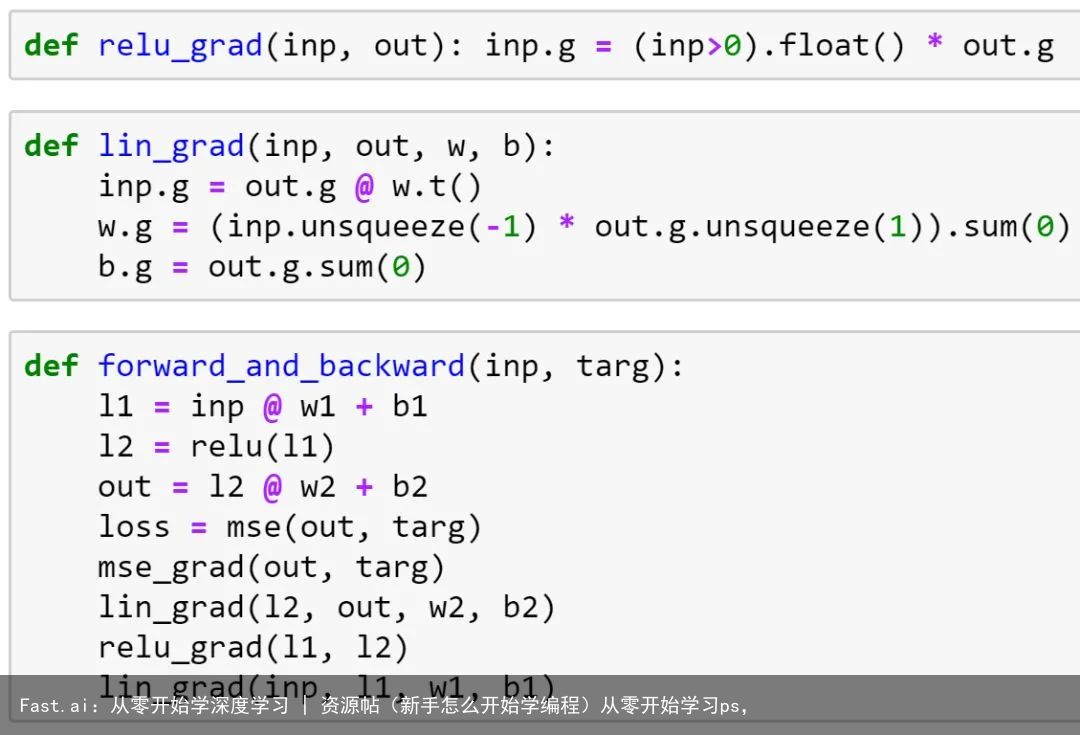
从头开始反向传播
论文讨论:
理解深度前馈神经网络训练的难度 - 引入 Xavier 初始化的论文
Fixup 初始化:无规范化残差学习 - 强调规范化的重要性,训练未正则化的 10,000 层网络
第9课:损失函数、优化器和训练循环
在上一课中,关于 PyTorch 的 CNN 默认初始化的问题非常突出。为了回答这个问题,我做了一些研究,于是就有了第 9 课。学生经常会问“我该怎么做研究”,这是一个很好的小案例研究。
我们将深入研究训练循环,并展示如何使其简洁灵活。首先,我们简要介绍一下损失函数和优化器,包括实现 softmax 和 cross-entropy loss(以及logsumexp技巧)。然后,我们创建一个简单的训练循环,并逐步重构它,使其更简洁、更灵活。在这个过程中,我们将学习 nn.Parameter 和 nn.Module,并了解它们如何 与nn.optim 类一起工作。我们还将看到 Dataset 和 DataLoader 如何真正起作用。
掌握了这些基本部分之后,我们将关注 fastai 的一些关键模块:Callback、DataBunch 和Learner,包括它们的作用和实现。我们将编写大量回调来实现许多新功能和最佳实践!
论文讨论:
自标准化神经网络(SELU)
深度线性神经网络中学习非线性动力学的精确解(正交初始化)
你需要的只是一个很好的初始化
深入研究整流器:ImageNet 分类表现超越人类 - 2015年 ImageNet 获奖论文,介绍了ResNet 和 Kaiming 初始化。
第 10 课:深入模型
第 10 课,我们将深入探讨回调和事件处理程序的基本概念,在 Python 中实现回调的许多不同方法,并讨论其优缺点。之后,我们将快速回顾一些其他重要的基础知识:
__dunder__ Python中的特殊符号
如何使用编辑器导航源代码
方差、标准差、协方差和相关性
SOFTMAX
控制流程的例外情况
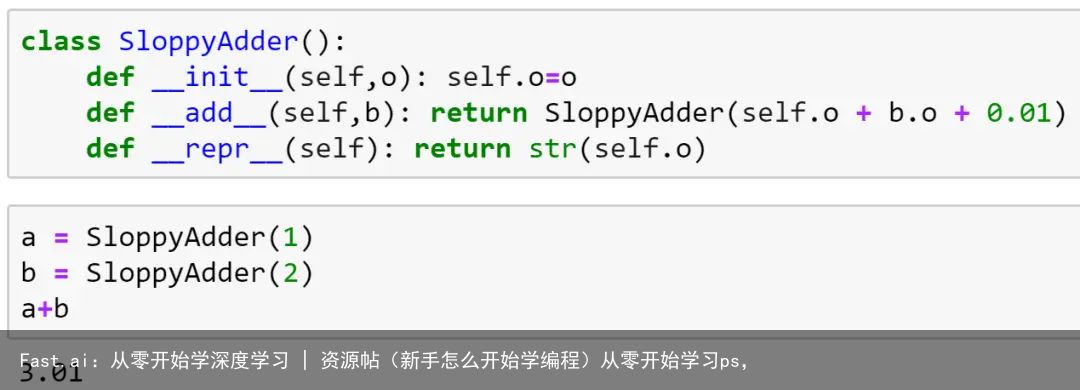
用 Python 的特殊方法创建类似于内置的对象
接下来,我们使用创建的回调系统在 GPU 上设置 CNN 训练。

我们将在本课程中创建一些回调
本课程主题:探索模型内部以了解它在训练过程中的表现。
论文讨论:
批量标准化:通过减少内部协变量偏移来加速深度网络训练
层规范化
实例规范化:快速程式化的缺失成分
组规范化
重新审视深度神经网络的小批量训练
第 11 课:数据块 API 和通用优化器
本课程将简要介绍一种称为分层顺序单元方差(LSUV)的智能简单初始化技术,从头开始实现,之后用上一课中介绍的方法来研究这种技术对模型训练的影响。
接下来将探索 fastai 的精华:Data Block API。在第 1 部分课程中我们已经讲过如何使用此 API,本课程将学习如何从头开始创建它,学到很多关于如何更好地使用该 API 并进行自定义的知识,包括:
获取文件:学习 os.scandir 如何提供一种高度优化的方式来访问文件系统,os.walk 提供了一个强大的递归树步行抽象。
转换:创建一个简单但功能强大的列表和函数组合,以即时转换数据
拆分和标签:创建灵活的功能
DataBunch:DataBunch 是 DataLoader 的一个非常简单的容器
接下来,我们构建一个新的 StatefulOptimizer 类,说明现代深度学习训练中使用的几乎所有优化器都只是这一类的特殊情况。我们使用它来增加重量衰减、动量、 Adam 和 LAMB 优化器,并详细了解动量变化训练的方式。
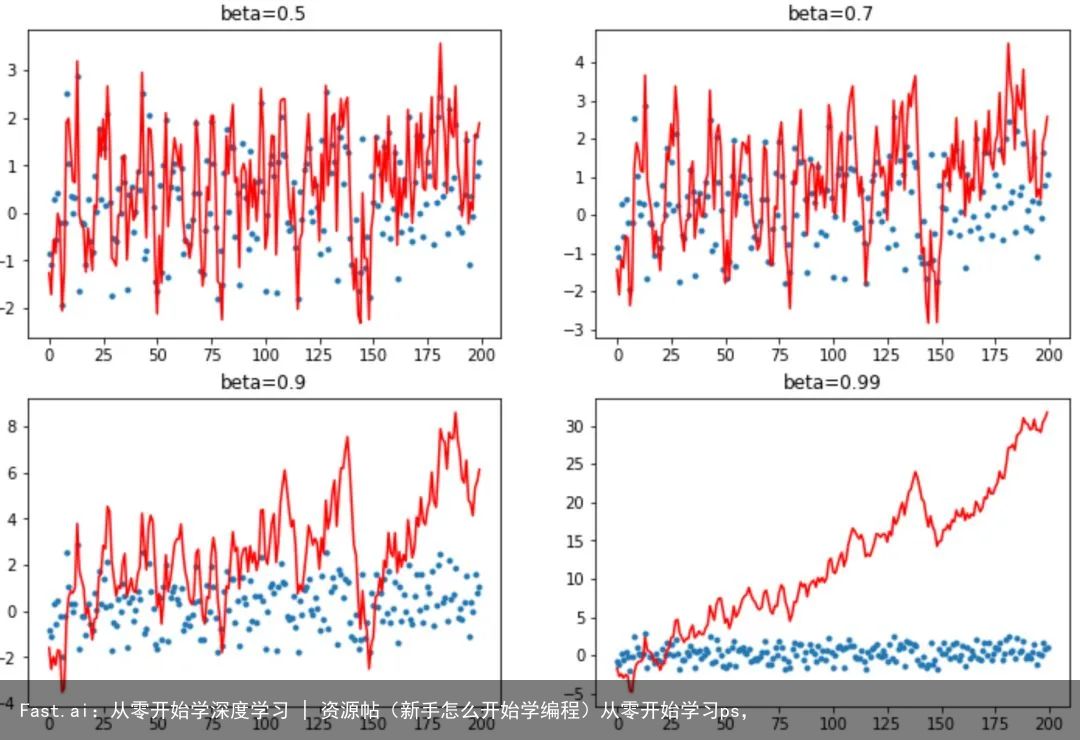
不同动量对综合训练实例的影响
最后,我们将研究数据增强,并对各种数据增强技术进行基准测试。我们开发了一种新的基于GPU 的数据增强方法,可以极大地提高速度,并允许添加更复杂的基于 warp 的转换。

使用 GPU 批量级数据扩充极大地提高了速度
论文讨论:
L2正则化与批量和权重归一化
规范很重要:深度网络中高效准确的规范化方案
重量衰减正则化的三种机制
Nesterov 的加速梯度和动量作为 Regularised Update Descent 近似值
Adam:一种随机优化方法
将 BERT 训练前时间从 3 天减少到 76 分钟
第12课:高级训练技巧;从零开始创建 ULMFiT
我们在第 12 课中实现了一些非常重要的训练技巧,所有这些都使用了回调:
MixUp,一种数据增强技术,可以显著改善结果,特别是数据较少或可以训练较长时间时
标签平滑,与 MixUp 配合使用效果特别好,当有嘈杂的标签时,可以显著改善效果
混合精确训练,在许多情况下训练模型的速度提高约 3 倍。
MixUp 扩充示例
我们还实现了 xresnet,这个经典 resnet 架构的调整版本有了实质性的改进。而且更重要的是,它可以更好地洞察如何让架构运行良好。
最后,我们将展示如何从头开始实现 ULMFiT,包括构建 LSTM RNN,以及处理自然语言数据以将其传递到神经网络所需的各个步骤。
ULMFiT
论文讨论:
Mixup:经验风险最小化之外
重新思考计算机视觉的初始架构(标签平滑在第7部分)
基于卷积神经网络的图像分类技巧
用于文本分类的通用语言模型微调
第13课:深度学习 Swift 基础知识
到第 12 课结束时,我们已经完成了从头开始构建了 Python 的大部分 fastai 库。接下来用 Swift 重复这一过程就行了!最后两节课由 Jeremy 和 Swift 的原始开发人员 Chris Lattner 以及Google Brain 的 Swift for TensorFlow 项目负责人共同教授。
Swift 代码和 Python 代码看起来并没有很大差别
在本课中,Chris 将解释 Swift 是什么,以及它的设计目的。他会分享有关其发展历史的见解,以及为什么他认为 Swift 非常适合深度学习和数字编程。他还讲解了一些关于 Swift 和TensorFlow 如何在现在和将来融合在一起的背景知识。接下来,Chris 展示了一些关于使用类型来确保代码错误更少的内容,同时让 Swift 为你找出大部分类型。他解释了我们启动项目需要的一些关键语法。
Chris 还解释了编译器的概念,以及 LLVM 如何让编译器开发更容易。之后,他展示了如何直接从 Swift 访问和更改 LLVM 内置类型!由于编译和语言设计,基本代码确实运行得非常快, 比Chris 在课堂上展示的简单示例快了大约 8000 倍。
了解Swift中`float`的实现
最后,我们研究了在 Swift 中计算矩阵乘积的不同方法,包括使用 Swift 来表示 TensorFlow 的Tensor 类别。
第14课:C 交互操作;协议;融合
今天的课程首先讨论 Swift 程序员在普通 Swift 中编写高性能 GPU 代码的方式。Chris Lattner讨论了内核融合、XLA 和 MLIR 这些让程序员兴奋地技术,它们很快就要在 Swift 实现。
之后,Jeremy 谈到了现在可用的东西:非常棒的 C 交互操作,展示了如何使用它来快速轻松地通过与现有 C 库接口,使用 Sox 音频处理,以及 VIPS 和 OpenCV 图像处理快速轻松地获得高性能代码。
Swift C 交互操作
接下来,我们在 Swift 中实现了 Data Block API!嗯...实际上在某些方面它甚至比原始的 Python 版本更好。我们利用了一个非常强大的 Swift 功能:协议(又称类型类)。
Swift 中的数据块 API!
最后,我们把通用优化器、学习器、回调等放在一起,从头开始训练 Imagenette!Swift 中的最终版 notebooks 展示了如何构建和使用 Swift 中的大部分 fastai.vision 库,但这两节课没能涵盖所有内容,所以一定要研究 notebooks,学习更多 Swift 技巧......
更多信息
跳过 FFI:C交互操作嵌入Clang
价值语义,由@AlexisGallagher 教授
张量理解:框架不可知的高性能机器学习抽象
 支付宝扫一扫
支付宝扫一扫 微信扫一扫
微信扫一扫