我是这样从零开始用深度学习做狗脸识别 ios App的(ps零基础自学)从零开始学习ps,
原标题:我是这样从零开始用深度学习做狗脸识别 ios App的
雷锋网按:本文为雷锋字幕组编译的技术博客,原标题What Ive learned building a deep learning Dog Face Recognition iOS app,作者为Octavian Costache。
翻译 | 汪宁 王飞 刘泽晟 整理 | 凡江
我做了一个狗脸识别的深度学习ios应用,并想跟你分享这些心得。
我是一个初创公司的软件工程师。曾经有段时间在谷歌工作,做谷歌财经图表和Multiple inboxes,并主管谷歌地图的业务。最近,我开了一家叫Spring的购物公司。同时,我也是一个创业者,在空余时间里我喜欢做一些副业。

几个月前,我开始做一个用于狗狗拍照app的脸部过滤器。当你将app对着你的狗时,这个app就会将这个过滤器作用在狗的脸上。有9200万张照片被标记为dogsofinstagram——你可能会发现有一些用户不在其中——创造人们想要的东西是额外的动力:
我需要
建立一个深度学习模型,提取狗的面部特征。
在iPhone上实时视频的顶部运行
使用ARKit显示3D过滤器(二维的表示不是那么酷)
从对深度学习一无所知到做出一个还不错的app。我想要分享我在每一步中所学到的经验。
我希望那些刚接触深度学习的人会觉得这些方法很有用。
第1步:深度学习大都是现成的
我需要回答的第一个问题是“这是可能的吗?”。我的问题容易处理吗?我应该从哪开始?
一些简单的搜索告诉我该学习TensorFlow对象检测教程、研究论文,或者如何用现成的代码构建一个有边界框的检测器。
我的问题看起来是可以解决的(人们得到的各类结果在我所需要的范围内),但没有现成的东西可以方便地用到我的用例中。试图弄清楚如何修改现有的教程让人恼火。
在阅读博客文章的过程中,我开始转向最基本的网络课程,从基础开始。事实证明这是一个非常好的决定。
在这个过程中,我了解到:
Andrew Ng的课程是关于卷积神经网络的课程(这是关于深度学习的一系列课程的第三部分)是学习应用于计算机视觉的基础概念和工具的一个好地方。没有它,我什么也做不了。
Keras在TensorFlow上是一个高级的API,它是最容易使用的深度学习模型。TensorFlow本身对于初学者来说太底层,会让初学者感到困惑。我确信Caffe/PyTorch也很棒,但是Keras真的帮了我的忙。
Conda是管理python环境的一种很好的工具。Nvidia-docker也很棒,但是只有当你可以使用GPU的时候才有必要使用它。
刚开始时,你很难从网络教程中学习最基本概念。如果你从更适合你的课程或书本中学习基本的核心概念。它将使你的学习更容易。
第2步:弄清楚如何实现特征点检测
用我最近发现的基本知识,我已经开始着手研究如何实现我的自定义模型。
“对象分类”和“对象检测”在今天已经是现成的了。我想要做的不是这些,而是后面这个,在文献中这个词是“特征点检测”(Landmark Detection) ,用术语概括我要做的事情会更方便一点。
现在,新的问题。什么样的模型是好的?我需要多少数据?我该如何给数据贴上标签?如何去训练数据呢?一个好的最小可行开发工作流程又是怎什么样?
第一个目标是让一些程序运行起来。以后我可以再去做一些提升质量方面的工作。俗话说在你跑之前先得学会走。
我的心得:
我用来标记左眼/右眼/鼻子的工具,自己设计的,起来很糟糕,但是很实用。
建立自己的数据对用户界面进行标注是一个非常好的想法。其他已有的标签对我来说没用,它们只适用于Windows,要么就是做的太多了。后来,当我需要对我所标注的数据进行修改(比如添加新的特征点)时,这种灵活性确实很有用。
标记速度很重要。我每小时至少可以标记300张照片。即每12秒就可以标记一个图像。标记8000张照片只需要26小时。如果你想标记数据的真实数量,那么每一秒都很重要。建立我自己的标记集有一定的前期成本,但实际上帮助了你之后的工作。
手工标记数据可以让你很好地了解模型的内容。
预处理图像最初看起来像是一个细节,但后来证明是很关键的,我花了几天时间来理解如何修改它。查看Stack Overflow上的解答——是否在正确的位置调用preprocess_image是程序是否运行的关键。
虽然并不是很精确,但程序已经可以就位了。一个模型输出并不离谱的东西,这让我很开心。
这种微妙的黑盒子的感觉——在正确的地方做正确的事情时才会成功——这种感觉在几乎每一步都存在。
跟踪缺陷、识别问题、缩小问题的范围——在一般软件工程中是正常的——在今天的深度学习开发中并不那么容易。
对于像我这样的初学者来说,弄清楚这个问题显得梦幻而偶然,而不是深思熟虑的结果。我不清楚这个行业里是否有人知道如何做好这一点——感觉更像是每个人都在试图解决这个问题。
大约三周后,我就做成了一些事情:我可以给数据贴上标签,在上面训练模型,用一张照片在Jupyter Notebook运行那个模型,然后得到真实的坐标(带有可疑的位置)作为输出。
第3步:确保模型在iOS上运行
现在有了一个简单的工作模型,我的下一步是确保它能在一个手机上运行,并且运行得足够快。
Keras/TensorFlow模型不能在iOS本地上运行,但是苹果有自己的神经网络运行框架CoreML。在iOS上运行.mlmodel 可以通过教程代码完成。如此简单的过程让我被它征服了。
但是,即使是这个简单的转换步骤(从.h5 到.mlmodel
)也不是没有挑战的。
苹果将一个.h5模型转换成一个.mlmodel模型的工具(称为coremltools),是一个半成品。 使用pip安装的版本在box外无法运行,我必须使用python2.5在conda环境中从源代码构建它
,打补丁。嘿,至少它有用。
弄清楚如何在手机上预先处理输入图像,就像模型所期望的那样,却出人意料的不简单。我在stackOverflow提问,或者搜索博客文章,可什么都没有。我最终通过给Matthijs Hollemans发送陌生邮件来找到了我的答案,让我惊喜的是他的答案使我脱离困境!他甚至有一篇关于这个问题的博客文章。如果没有他,我不会发现这篇文章。
事实证明,整个深度学习工具链仍在开发中。在深度学习领域,事物变化很快。
另一方面,我喜欢团体小而富有活力,互帮互助的感觉。如果你像我一样,有点迷糊,不要犹豫,直接发邮件问。最差也不过是没有人回答。最好的情况却是有个好人帮了你。就像Matthijs。感谢!
我的模型在实体机上以每秒19帧的速度运行了,这就像一个神奇的划时代事件。有了这个基础,现在我可以致力于提高质量了。
第4步:让模型运行得更加完美
这的确需要一些时间。我该怎么做才能让我的产品在深度学习模型外也表现良好?再多点数据?使用不同的顶层?使用不同的损失函数?层中使用不同的激活参数?太麻烦了!
循序渐进似乎是最好的。不断测试,训练,和前一次的运行情况进行比较,看看哪一个办法起了作用。刚开始用少量的数据,慢慢地扩大数据集。少量的数据意味着较短的训练时间。一旦利用大型数据集进行训练。运行一次得等待24小时是很常见的,这并不是真正的快速迭代。
数据扩充是可能会出错的代码。开始的时候可以略过这一部分,运行的时候可以不运行这一部分代码,然后一点点增加数据扩充部分的代码。要保证代码是稳定的。你的模型应该始会和你输入的数据一样好。准备好时间会被浪费掉,准备好学习最优做法需要时间。你必须要不断往前走并且不断往下做,不然你是不会从错误中学到任何东西的。往前走,要勇于犯错。
这是我试着做这个项目的时所学到的:
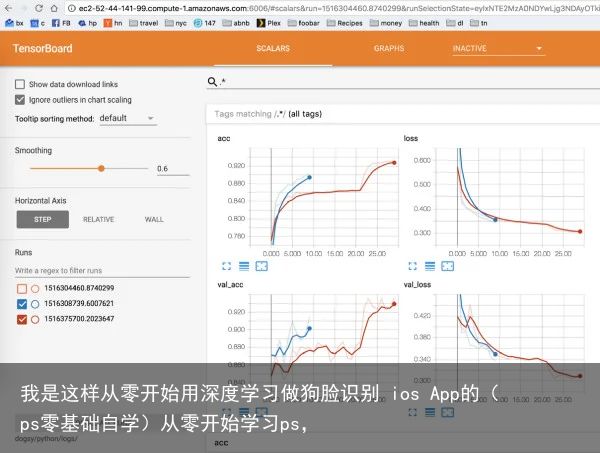
这一点似乎显而易见----使用TendorBoard对迭代开发能够达到数量级的提高
从我的数据生成器中对图像数据进行调试,这能帮助我找到影响我模型的图像处理的Bug。就像我对镜像照片时,虽然我并没有交换左右眼。
和那些经常训练模型、有经验的人进行交谈,这节省了我很多时间。一个罗马尼亚的机器学习团队和几个慷慨的朋友证明这很重要(感谢Csomin Negruseri , Matt Slotkin , Qianyi Zhou以及Ajay Chainani)。让别人来主动问你遇到什么困难,这是不可能。
通常来说,不按照默认规则来做并不是一个好主意。比如,当我尝试着用fisheries competition上发布的一个博客做顶层时-- 博客里面的使用了 activation=relu ,虽然顶层呈现出来的结果很不错,但是 activation=relu 并不好。当我试着使用我自己的L1 LOSS损失函数时,呈现的结果比更加标准的MSE loss损失函数差很多。
编写一个数据生成器很有必要。数据扩充很重要。
当你运行教程时,在几百张图片上学习和训练第一个模型,一个CPU就足够了,使用GPU会显得累赘。
在GPU上使用一个真实的数据集(8000张图片)和一个数据生成器(80000张图片)进行训练十分重要,即使它要花24小时。
亚马逊的GPU对个人开发来说比较昂贵,在24小时一次的迭代当中,大概每小时花一美元,花费会迅速增加。谢谢Cosmin让我通过SSH进入你的电脑,让我能够免费使用你的GPU。

检测有点不太准确。当然,这只是我测试用的狗头,一个从亚马逊买的狗面具。绝不会移动,总是很开心地望着照相机!
尽管并不完美,但是最后的结果表现得相当好,足够可以用来做一个app。
并且我感觉,如果我是一个全职的机器学习工程师,让其更好是很有可能的。
但是像其他的产品一样,最后的百分之二十进程会花掉百分之八十的时间,我认为在下一个版本中,我必须要将这部分工作纳入其中。
如果你对你的产品羞耻感较弱,你可能会需要花很多的时间才能完成这些工作,特别是对于业余项目来说。
第5步:搭建iOS应用,过滤器,然后把它们集成在一起
手上有了足够好的模型,现在可以放到Swift,ARKit上,并且事实证明,SpriteKit可以用于2D内容。iOS及其框架仍旧让我印象深刻。如果你能正确看待它,这些天能够在手机上做的事情的确很令人兴奋。
这个应用本身很基础,一个大的记录按钮,一个滑动切换过滤器,一个分享按钮。
大部分的工作是在学习ARKIT,然后弄明白它的限制。如何把3D模型放进去,如何从场景,灯光,动画和几何图形中添加和移除这些模型
在这个过程中我学到的:
ARKit很好。是的,添加3D内容很容易,很有意思,API也很棒。一旦你把某样模型放到场景中,它就很马上起作用。
ARHitTestResult表明,通过图片中的像素,它会返回给你像素的三维坐标,确实有用但是精度不够好。结果中百分之七十是在正确的位置,百分之三十出现在了错误的位置。这给我把过滤器应用在脸部识别上造成了困难。
备用计划:构建二维的过滤器。 SpriteKit,苹果的二维游戏引擎,使用起来十分简单--这个引擎有一个内置的物理引擎。使用和学习起来很有意思(虽然表面上是这样)。
第一代结合了CoreMl的ARKit技术让我大开眼界。
在几个星期之内,我就能够在实时的照相机视频流上运行我的深度学习模型了,抽取出脸部特征点,利用Arkit展示出三维的内容,使用SceneKit展示出二维的内容,处理的精度相当不错。
仅仅在两年前,为了相似的技术(用于人脸),SnapChat不得不花一亿五千万美元买下一个公司。现在iOS免费提供人脸标志检测,并且不像我的ARHitTestResult的结果,它的精确度很高。这种技术迅速商品化真是太不可思议了
再过几年,一旦iPhone背面有红外点,你的环境的3D映射应该变得相当好。
总结
对于深度学习的应用,人工智能的热潮和什么相关,iPhone当前所拥有的性能,以及ARkit,SpriteKit,Swift,我感觉自己对它们有了一个深刻的理解。
现在你还不能找到现成的深度学习模型,因为深度学习相关的一切都还不是很普遍,但是,在将来情况就会改善。
如果你跳过一些必要的步骤,以及一些必要的限制,对我来说就像技术在这篇博客的应用。
我不必深入神经网络的内部细节,也不必直接触碰任何TensorFlow相关的东西。
高层次的Keras远远够用了。一周的关于卷积神经网络基础的网络课程足够满足我的需要了。当然,这不会让我成为专家 ,但这能让我最小限度地得到一个可用的产品。
我开始相信苹果公司必须在手机业务之外开发增强现实技术。当他们推出 Magic-Leap-Equivalent产品时,构建增强现实会变得十分容易。ARKit已经让人印象深刻。
经过这次练习后,我对深度学习的理解更加深入,特别是在计算机视觉方面,感觉就像魔法一样。
能够从诸如照片这样简单的东西中提取的结构化数据的类型将是不可思议的。你买什么狗玩具,你还剩多少狗粮,你喜欢什么样的狗粮,你什么时候带狗去看兽医。你将能够从你的照片那样简单的事情中了解你与宠物(或你的宝宝,或你的伴侣)的关系的一切。
感谢阅读,希望对你会有帮助。如果你有任何建议,不要犹豫,我很愿意让我的的应用程序变得更好。
在应用商店下载这款应用,让我知道你的想法。 雷锋网雷锋网
另外, 非常感谢Cosmin Negruseri, Matt Slotkin, Qianyi Zhou 以及 Ajay Chainani ,感谢他们帮助我完成的应用以及评阅这篇文章。感谢Andy Bons为这个应用提供了最初的想法。
12 支付宝扫一扫
支付宝扫一扫 微信扫一扫
微信扫一扫